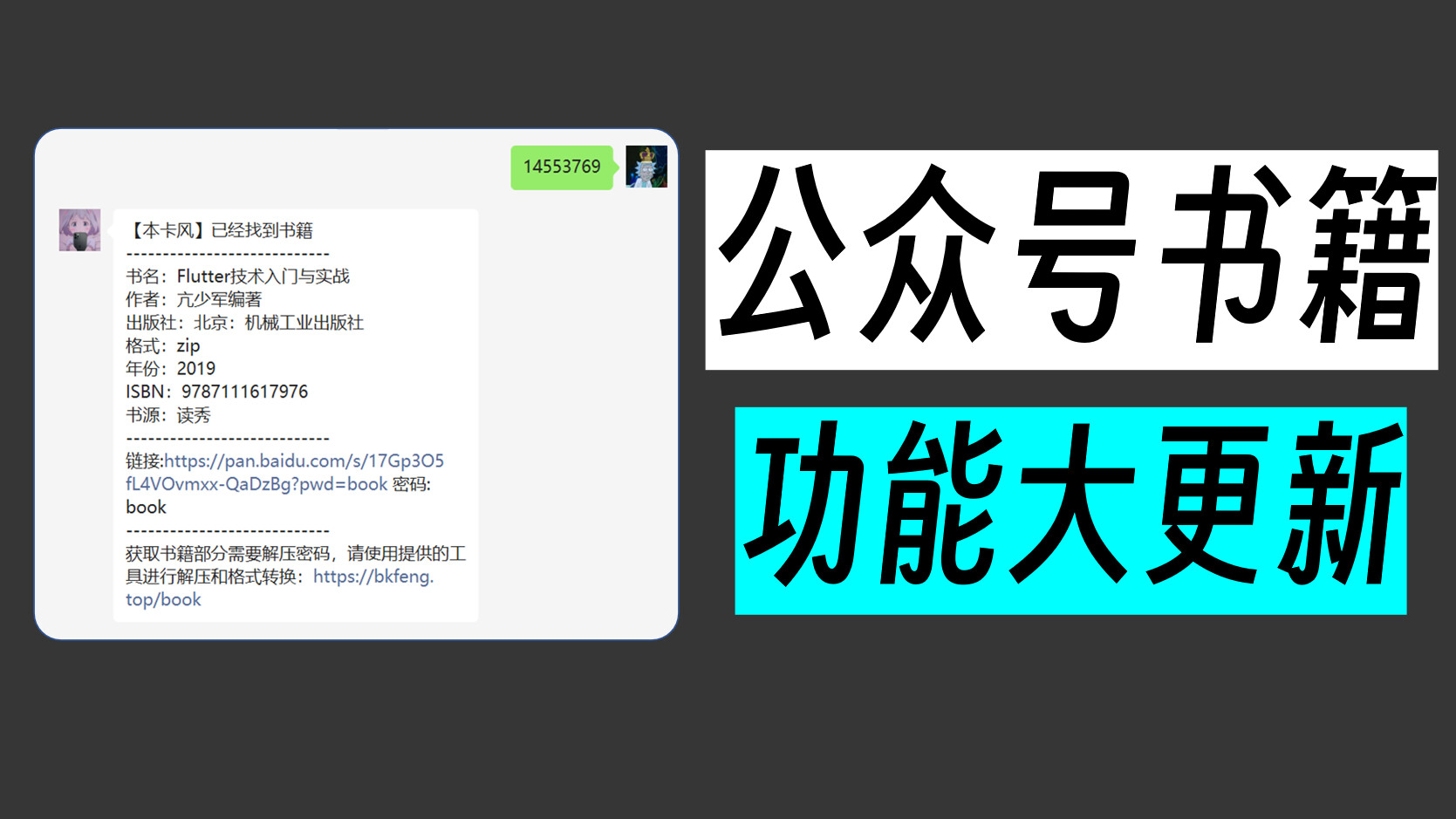
个人喜欢在读书时勾勾画画,遇到一些重要的知识或者内容希望能在图像PDF上便捷地做复制、搜索、高亮、划线等等操作。
但是我们公众号获取的书籍通常是图像扫描文件,最终的到的仅为单层PDF。
这种图像类格式的PDF不可进行搜索、复制文字等操作,这就很难受了。
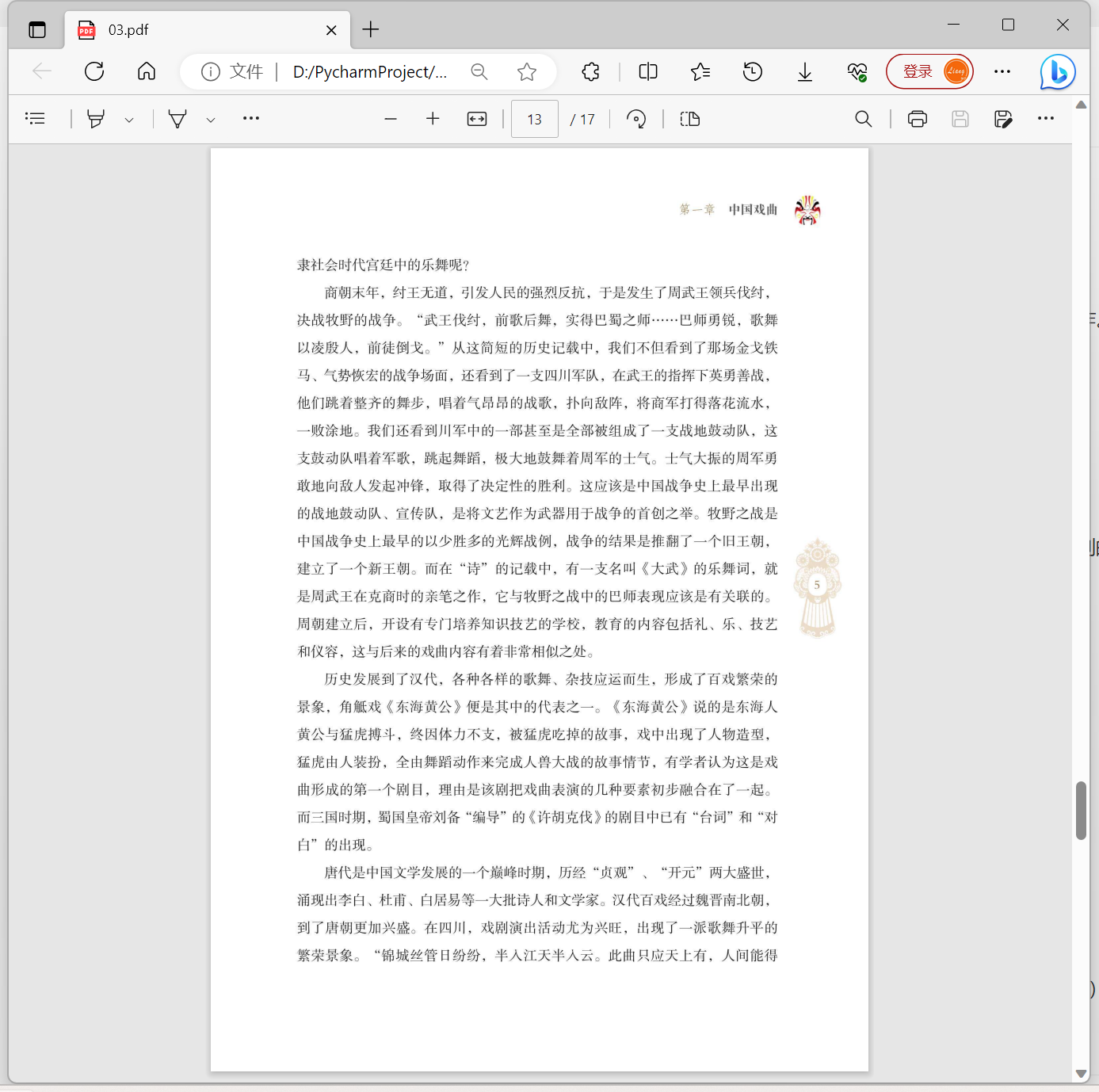
通常我们会进行OCR操作,将PDF变成可检索的图像格式的双层PDF
双层PDF的“双层”,指的是“图像层+隐藏文字层”,即在扫描图像上,再蒙一层不可见的隐藏文字,这样在阅读的时候,看到的是与原书完全一样的扫描图像,但是同时又可以对隐藏文字进行搜索、复制。
PDF文件的OCR,首选肯定是Abbyy,然后就是Acrobat啦。
大家可以通过B站以及谷歌获取相关教程,本文不过多介绍
下面介绍的方法,是在我们使用提供的PDG2PIC软件将PDG转换PDF的时候,顺便将合成的PDF文件变为可检索格式的双层PDF,从而省去转换出来PDF文件后又将PDF进行OCR的麻烦。
(本教程默认你已经安装了PDG2PIC软件,并且知道如何把一个压缩包解压为PDG目录,并且导入到PDG2PIC软件进行PDF合成)
教程开始
转换书籍时,想必大家都是通过PDG2PIC这个软件的吧
PDG2PIC是strnghrs开发的一款软件,大家转换PDF的时候也经常使用吧~
其中自带的OCR功能,但是如果你直接点击OCR但是无法转换的,还需要我们下载相关驱动
为什么不加这个功能的?作者是这么说的:
生成双层PDF:如果此选项被选中,则转换过程中启动OCR,生成隐藏文字,否则只转换图像,不管文字。由于需要时间,MODI的安装也不是电脑白痴随随便便就能搞定的,因此此选项缺省未选中,以免麻烦。
好了,下面是配置方法
1.下载PDG2PIC以及MODI_Engine
如果你已经有PDG2PIC软件,复制直接MODI_Engine.exe到相同文件夹,
或者也可以直接下载全部文件到一个目录
2.安装MODI
双层PDF的文字靠OCR生成,教程所用的OCR引擎是微软Office 2007自带的MODI(Microsoft Office Document Imaging)。
只需要打开Setup_MODI_From_Office2007SP3.exe进行一键安装

安装完成以后就可以直接进行OCR转换了.
OCR演示
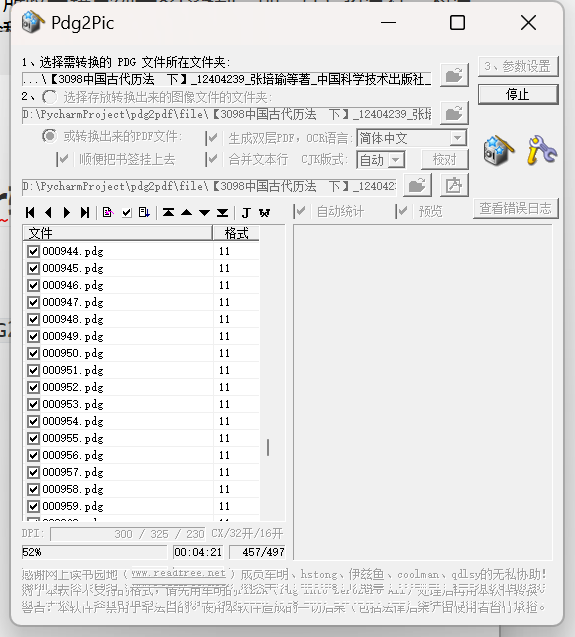
勾选“生成双层PDF”后开始转换
OCR和转换的过程还是很快的,平均0.5s一张
180页的PDF弄下来图像转换+OCR一个用了2分钟左右
转换好的文件我们可以直接复制以及文字标注啦!
遇到重要的知识点也不用担心复制不了
这是复制出来的文字与原文的对比,一眼看过去准确率还是挺高的~
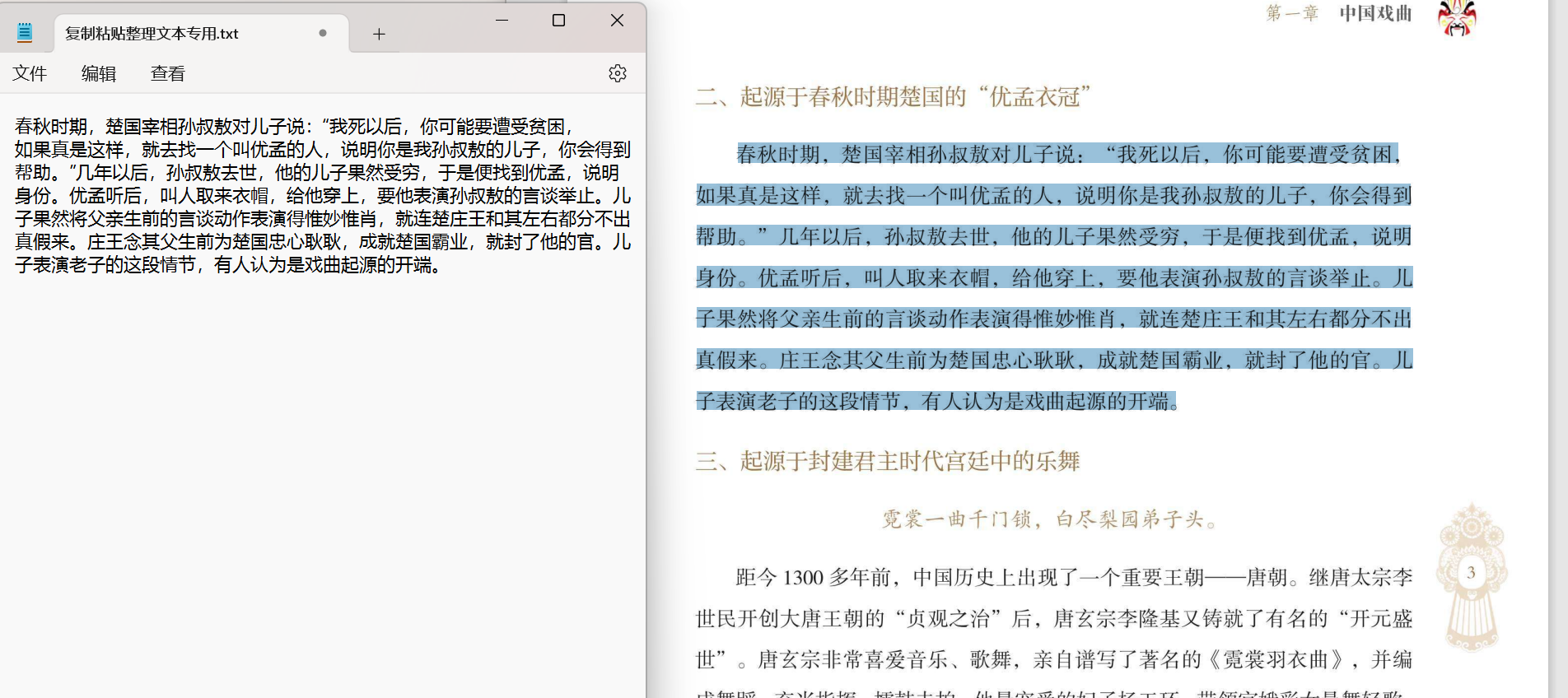
TIP
1.OCR结果不能保证100%准确性,其结果与图像分辨率、图像质量密切相关。
2.一些排版复杂,图像居多的文件,建议就别OCR了,以免结果太过搞笑。
3.关于软件OCR相关操作的几个选项:
- 生成双层PDF:如果此选项被选中,则转换过程中启动OCR,生成隐藏文字,否则只转换图像,不管文字。
在选中“生成双层PDF”后,下列选项才能生效: - OCR语言:一次只能选择一种语言,注意所选项必须与所识别的文字相匹配,例如想识别繁体字,就一定要选择“繁体中文”,否则识别出来的结果多半会很搞笑。
- 合并文本行:如果选中,则转换出来的PDF文件中的隐藏文本以行为单位,文件长度较小,但是字的位置不一定准确。如果未选,则以字(CJK)或词(非CJK)为单位,字的位置比较准确,文件长度略大。
- CJK版式:中、日、韩文字都有横排和竖排之分,本软件在一定程度上可以自动识别,如果对识别结果不满意,可以手工选择是横排还是竖排。此选项对OCR准确性没有影响,仅对隐藏文字采用的字体有影响。
- 去掉大于页面尺寸1/*的图表:MODI引擎在OCR中日韩语言时相当脆弱,在OCR前先对图像清理一遍是一个更安全的做法。判断是否是需要清除的图表。如果指定的比例是1,则所有页面都不会执行自动去除图表操作。
4.OCR纯中文或者纯英文都没有问题,有时候OCR中英文混排的时候,效果确实不如Abbyy,这个无解。但是软件的OCR转换可以满足大部分需求了。
5.为了软件失效,可以随时更新,以上软件链接公众号后台回复:getocr 获取
 wechat
wechat