





最近过完年比较有功夫
对公众号的书籍查找功能进行了优化更新
本来想自建书籍数据库,使用MySQL数据库
但考虑到数据量太大,仅读秀的资源去重后就有4120298条
而新加的Zlibrary库更是将近10000,000条,二者共计1500W左右数据
在磕磕碰碰遇到不少困难终于把书籍导入到数据库以后
我发现数据库在建立索引后,查询仍询比较慢(特别是全文查询)
最终我还是选择了接入别人的接口,这样可以实现相同的效果
毕竟别人做的搜索接口性能速度等方面应该比我的好不少(绝不是偷懒)
如果他的接口失效了,再使用自己的书籍数据库吧~
以下是公众号搜索的一些问题:
-
为什么我不去百度上的一些书站获取书籍而去公众号搜索呢?
公众号的书籍内容包括超星(读秀)和zlibrary的资源,二者涵盖市面上绝大部分书籍。你在公众号搜索不了那去百度上一些散乱的书站以及tb买书商家也比较难找了。
-
为什么下载的书籍压缩包要密码?
教程内提供了软件。使用软件压缩,会使用软件内置密码库进行一一尝试从而进行压缩操作。目前从网络中搜集来的资源密码有 300+个,解压软件后台在处理任务时会尝试这些密码,后续还会持续更新密码表,提升成功率。
-
发送ss号以后公众号说没有这本书,怎么办?
这么说的话你的书可能是20年以后出版的,对于20年以后的书,在超星库中并没有。
-
超星库与zlibrary有什么区别?
超星就是负责扫描国内的书籍的,获取到的大部分为扫描版,且需要转换;
而zlibrary是国际上知名的书籍获取网站,外文书比较多,也有一小部分较新书,获取到的书籍为pdf、mobi、epub等的文件。
-
怎么获取ss号?
ss即super star,是超星搞出来的一种针对每一本扫描书籍的号码
通过公众号搜索指令
cx你需要搜索的书名查询,不以“00”开头的数字为ss号另外,通过网站也可以获取ss号 https://www.xueshu86.com/
-
怎么获取zlibrary号?
通过公众号搜索指令
cx你需要搜索的书名查询,以“00”开头的数字为zlibrary号。 -
我用的是手机或者Mac电脑,怎么使用解压转换工具呢?
解压转换工具暂时只自测支持Window系统
如果你用的是手机或者Mac,可以使用这个网站来在线解压转换。
在公众号获取百度云链接后,使用该链接直接转换:https://pdg2pdf.online/convert
-
百度网盘链接失效了怎么办?
目前百度网盘分享后只保留1天,请尽快保存,并在下载后24小时内删除!
-
可以批量获取书籍吗?
可以批量转换吗?很抱歉,暂时不支持批量转换。考虑到目前服务器资源有限,批量获取资源将会导致滥用,因此暂时不会支持批量获取书籍。
-
解压软件报毒怎么办?
安全软件误报,吧安全软件关闭就行了。软件是无毒的可以放心使用。
-
提示公众号出现故障怎么办?
请联系管理员微信
bkfeng46,获知后会第一时间修复。 -
还有什么获取书籍的方法吗?
如果你理解能力电脑能力比较强,可以参考我们群内管理员
Eureka!写的这个教程 电子书文献论文搜索下载 依照这个教程公众号内可以获取的书籍这个方法也可以获取到 -
为什么文件没有书签呢?
每本书的书签都不同,需要和页码匹配进行编辑修改,所以我们大部分只提供简单的页码书签,部分文件无书签。想要获得完整书签教程内的下载工具软件,解压后软件包内有详细的书签编辑说明和书签编辑工具。
-
百度云下载速度慢?
如果你使用电脑浏览器,我推荐你用 软件小妹 的一个油猴脚本,基本可以满速下载。百度网盘简易下载助手

公众号书籍搜索指令如下

-
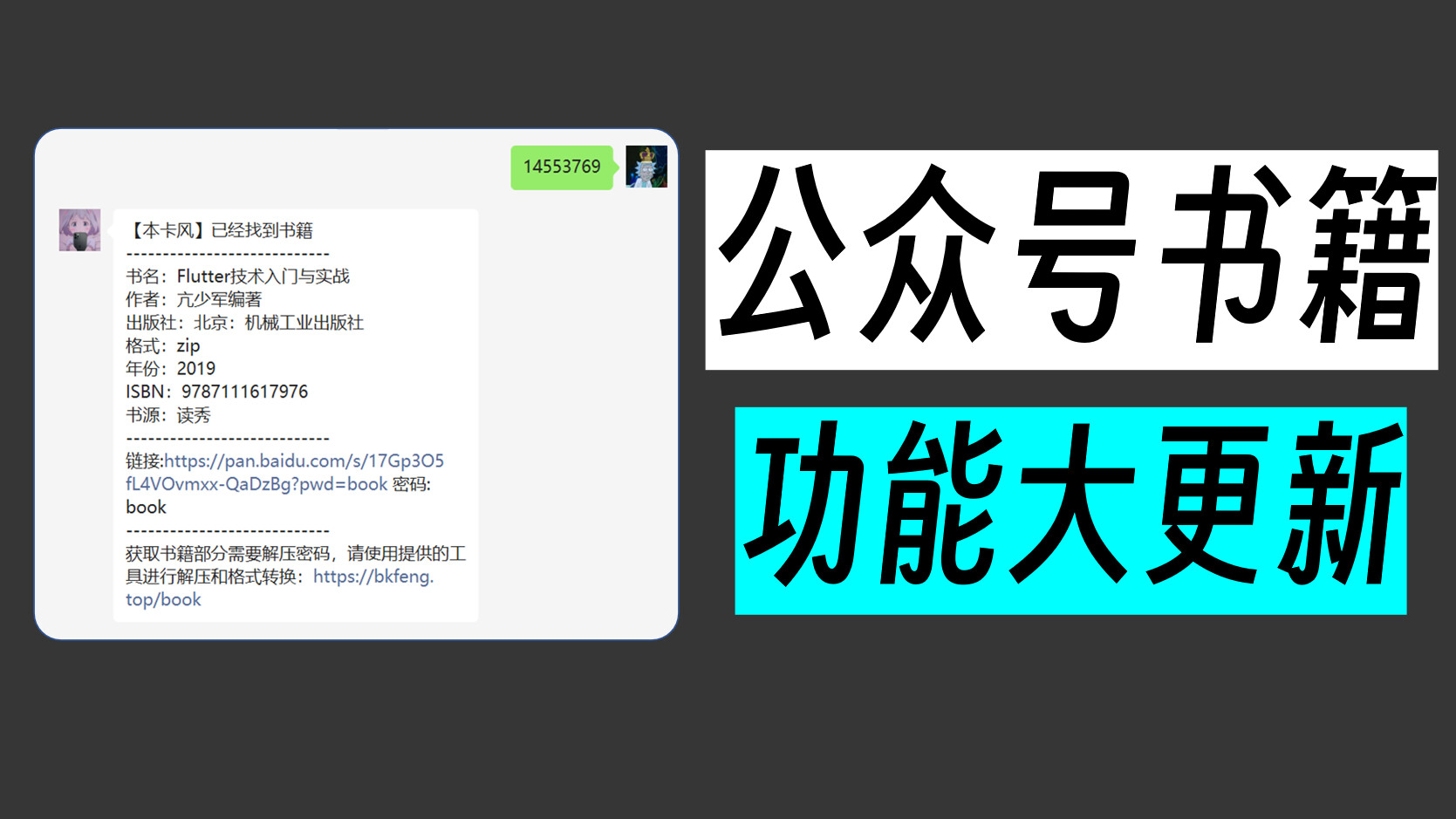
通过书籍id获取包含书籍的信息和下载链接
-
ssid为8为数字,可以获取读秀的资源(书籍下载后还需要进行解压和转换等一系列操作)
-
zlibid以00开头,可以获取zlibrary的资源(书籍下载后直接可以打开,无需转换)
书籍的ssid通过网站搜索、公众号搜索获取
书籍的zlibid暂时只能通过公众号搜索获取 -
-
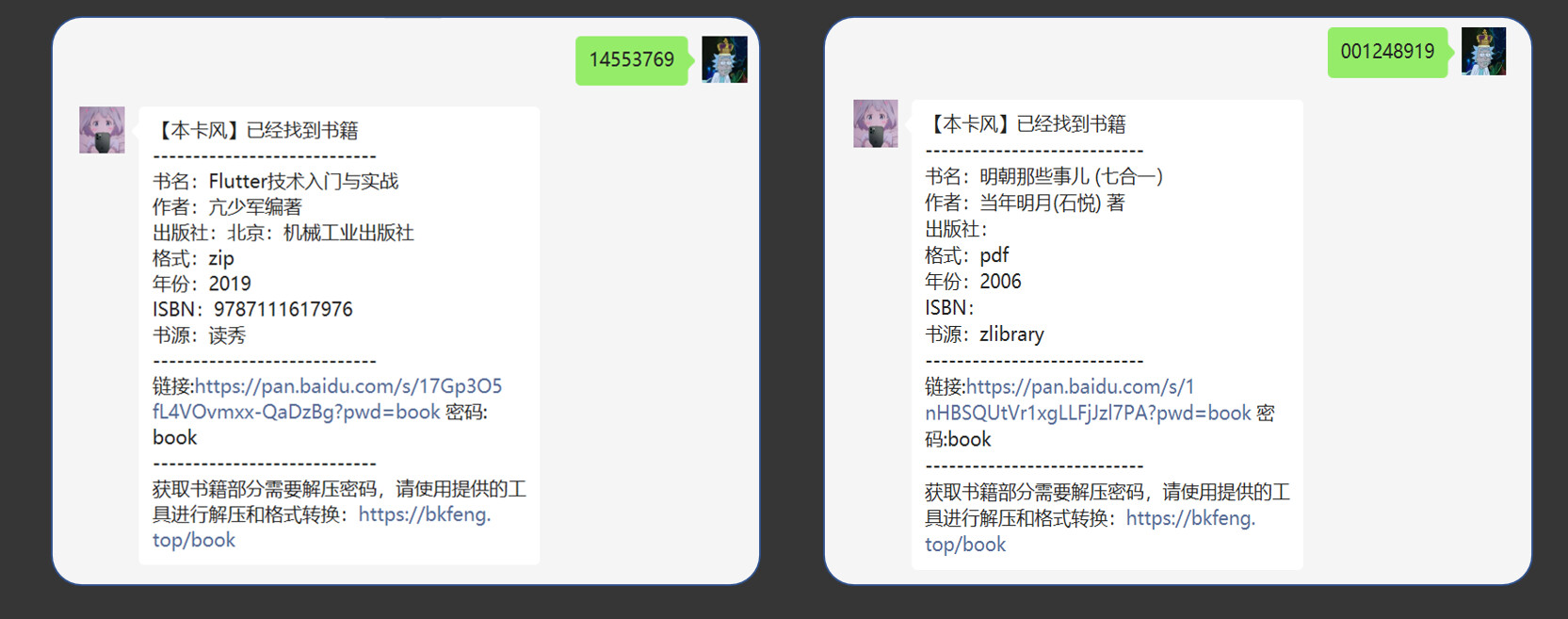
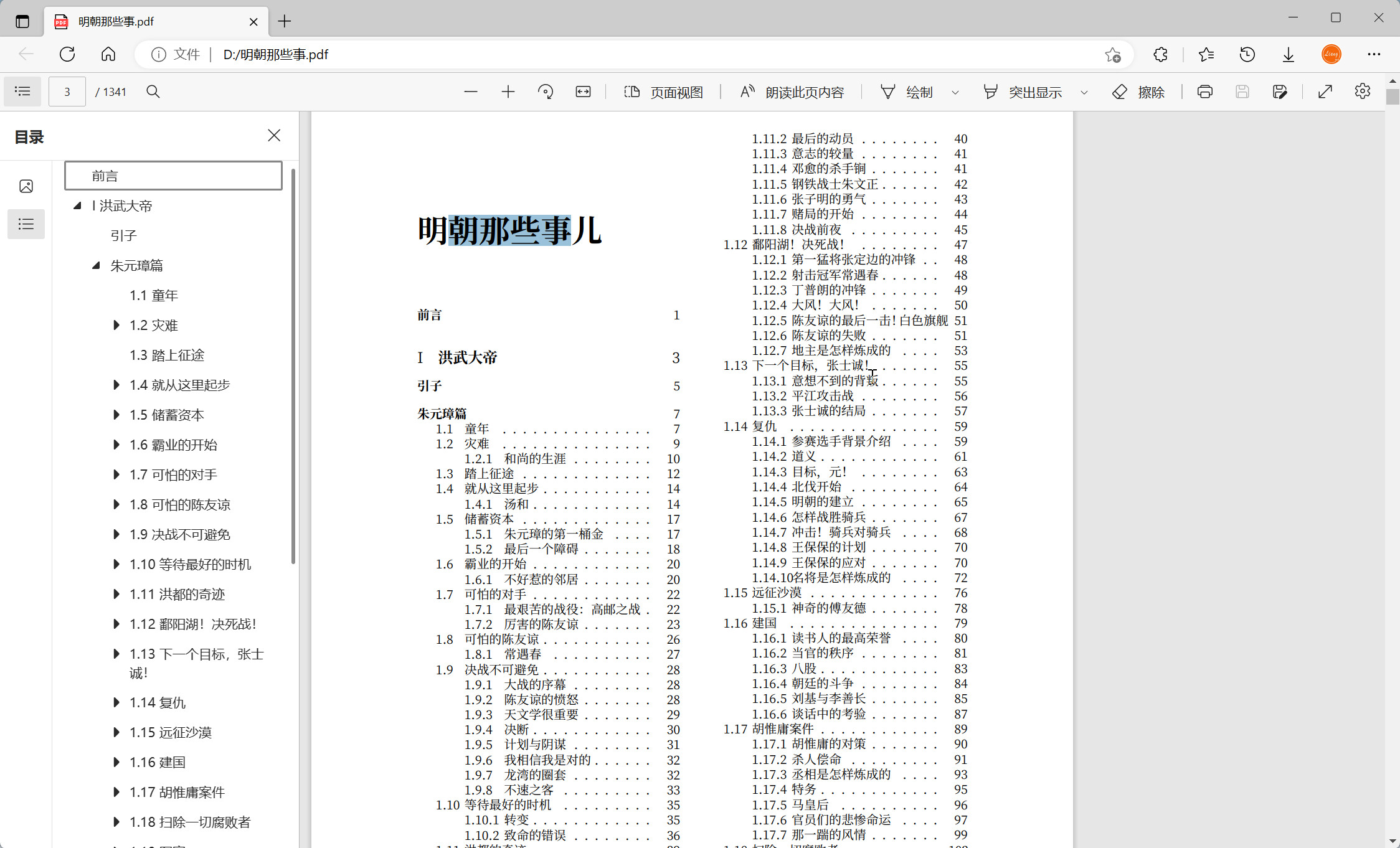
通过
cx你需要搜索的书名来搜索书籍如想要查询“三体”,就发送“cx三体"
此种方式的好处可以查询包括zlibrary和读秀的书籍
建议优先使用zlibrary的资源里的书籍(即书籍id为00开头)
因为该库的书籍文件为pdf、mobi、epub等无需解压的文件
读秀库的文件需要解压以及文件为扫描版,且文字不可复制和没有书签
再次回复书籍的id可以获得书籍的百度云链接
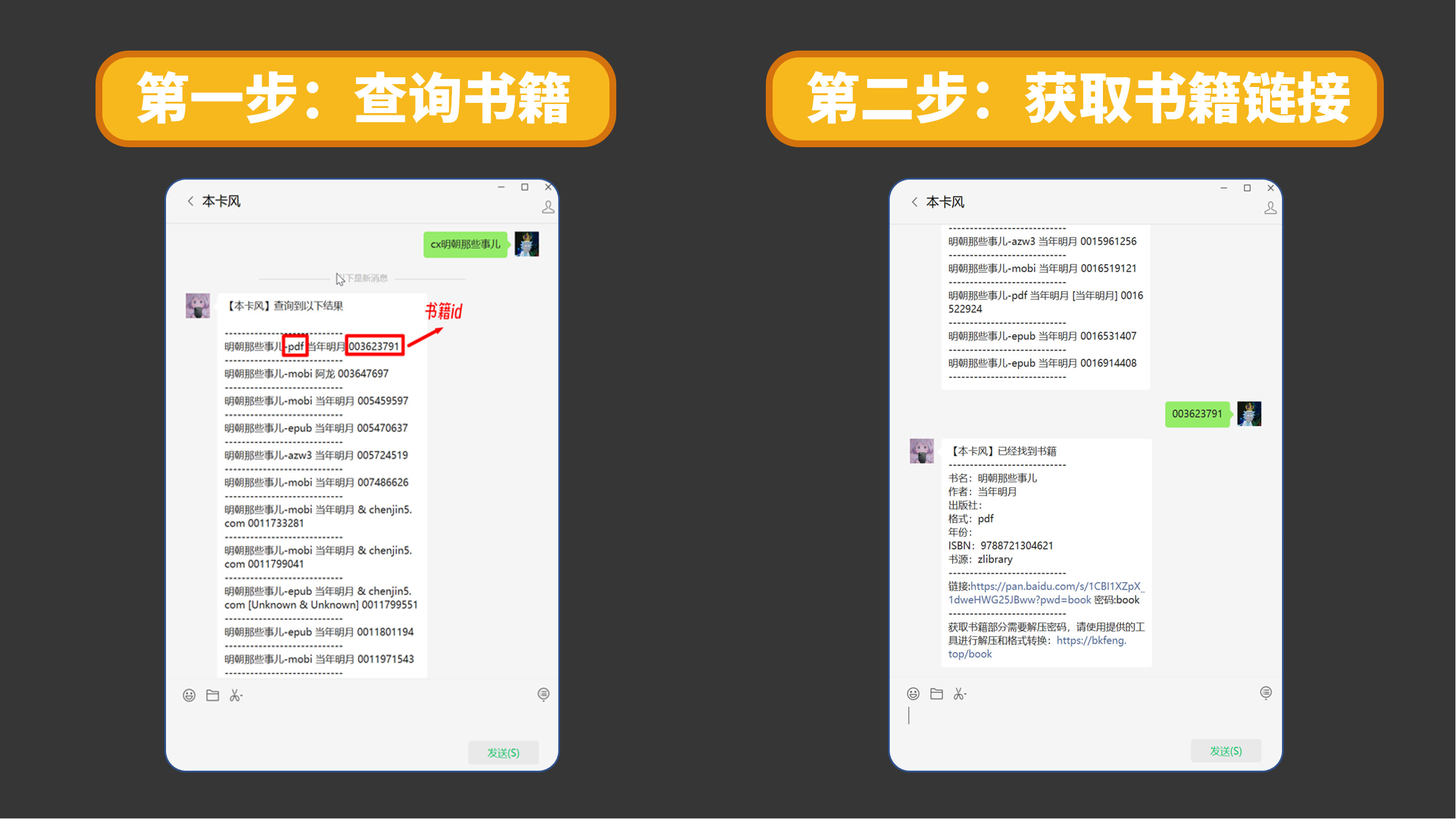
下载后即可获取一份带有书签的文字可复制的文件
-
通过
next进行查询结果的翻页操作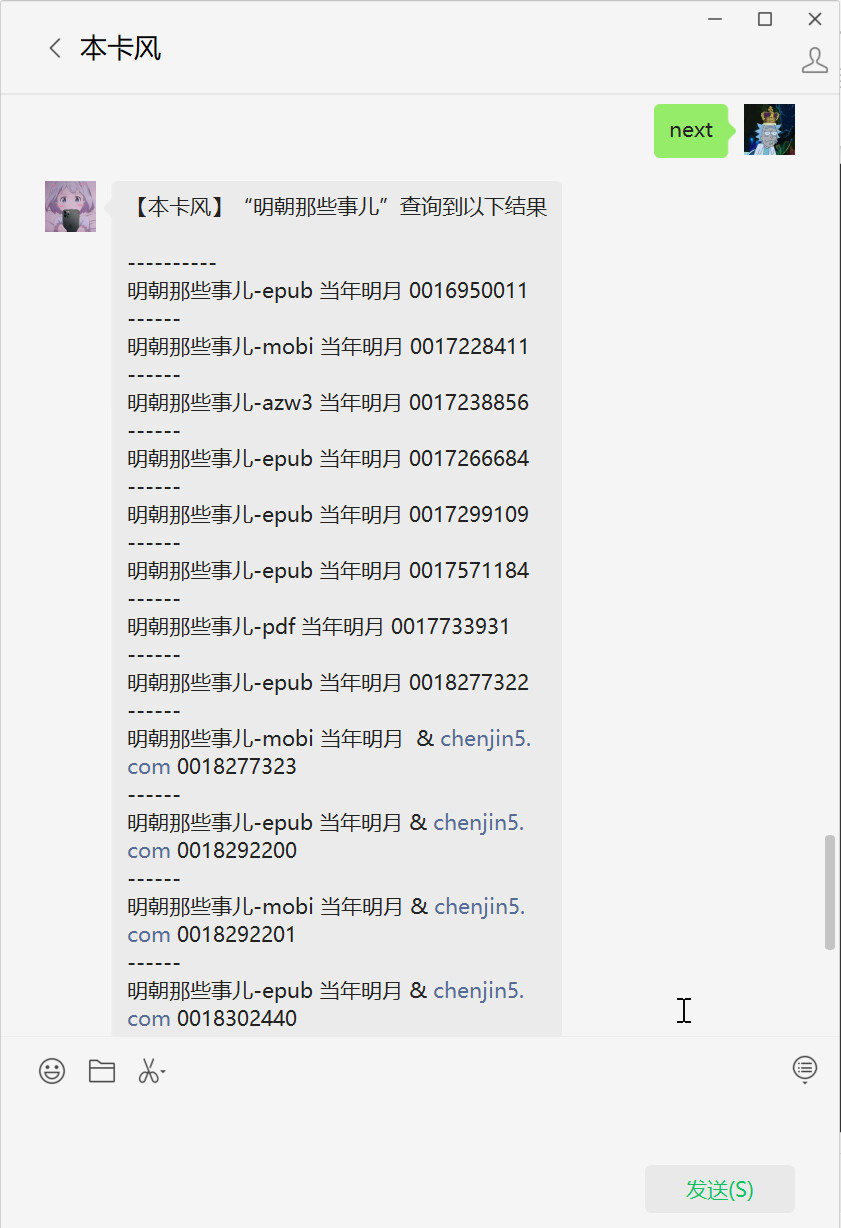
-
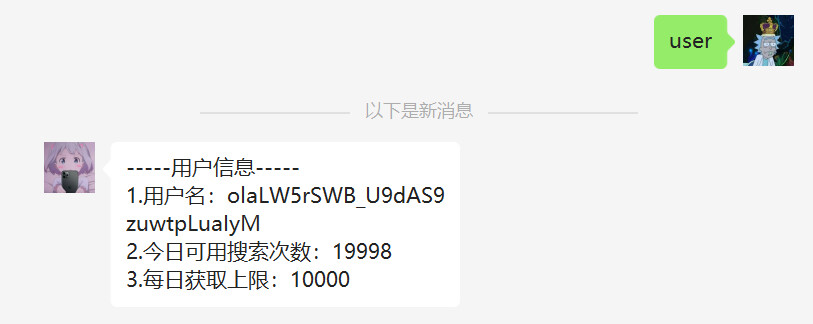
通过
user获取用户信息
以上就是目前为止公众号的所有指令,
目前公众号为节约资源,限制了每日获取次数。不过一般正常使用的话不会超过这个限制的。
因为以前老有一些人一天就发个几百本的书籍过来
 ](
]( wechat
wechat

