记一次python优质云盘资源爬取
最近见到一个网站,里面的内容挺丰富的哈!!
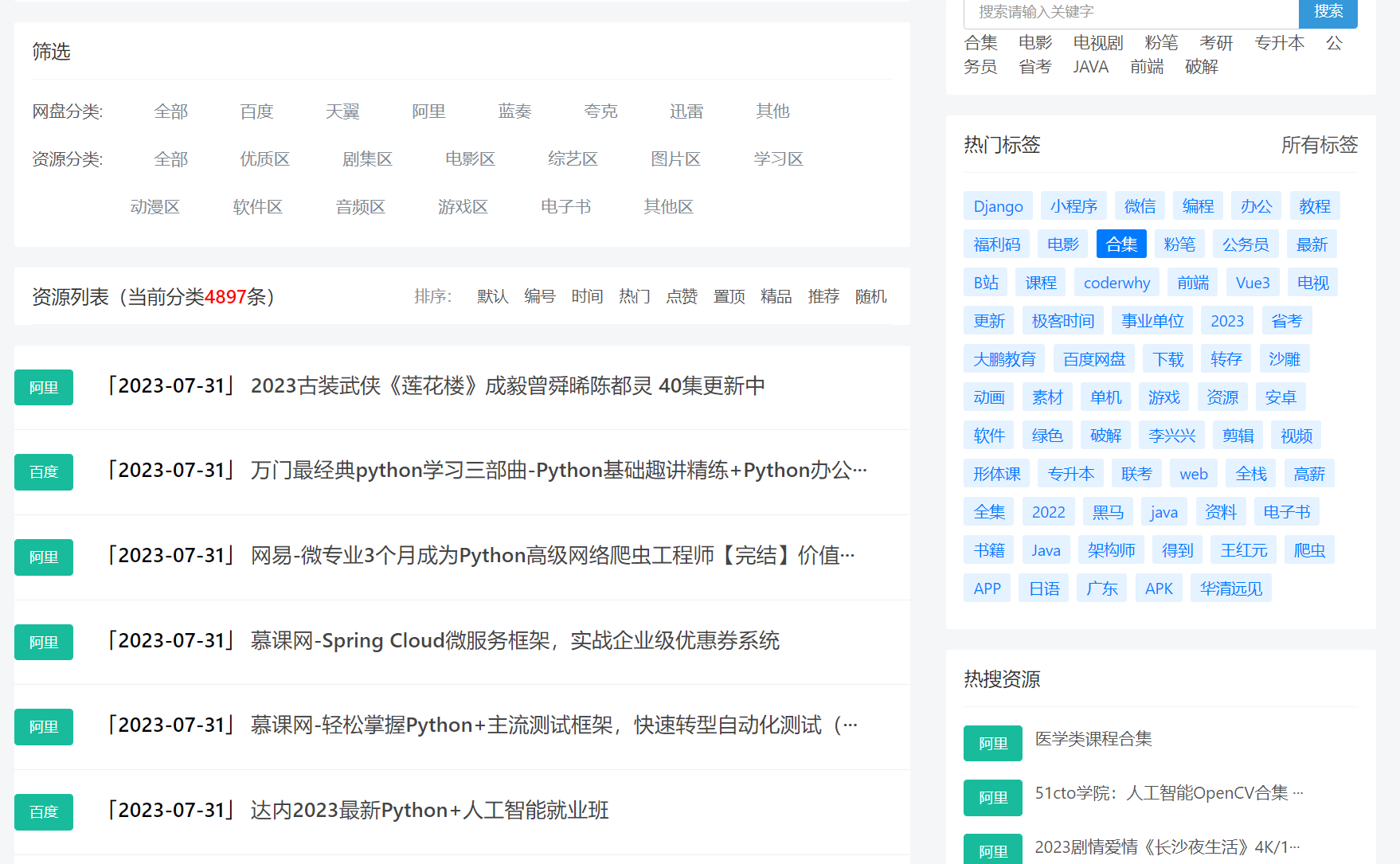
里面的资源也一直在更新
虽然目前该网站资源免费,登录就可以获取
但就着学习的态度,决定把这个网站4000多条资源爬取一遍
通过观察发现,网站的网站格式如下
1
2
3
4
5
| https://****.org/skills/4065.html
https://****.org/skills/4066.html
https://****.org/skills/4173.html
https://****.org/skills/4183.html
https://****.org/skills/4184.html
|
不难发现,规律是 https://****.org/skills/****.html
只要我们把从1开始一直爬取到网站目前更新到的数字就可以了
但真的这样吗?
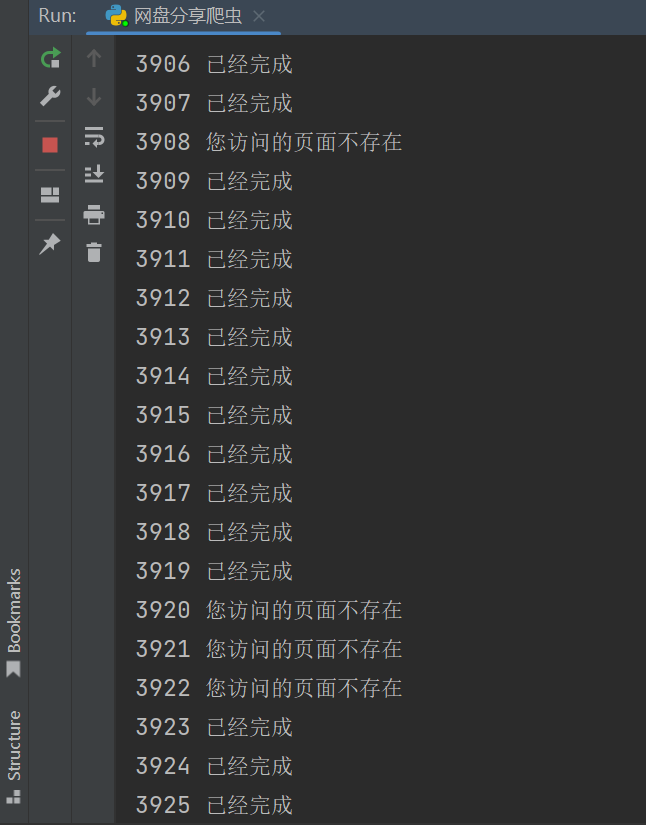
实则不然,期间发现一些链接会有不存在的情况

很简单,只需要判断一下网页有没有“访问的页面不存在”这样的字符就行了
一顿操作下来,得到代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| import requests
from bs4 import BeautifulSoup
import csv
import time
def get_info(num):
headers = {'cookie': '填写你的cookie'}
url = "https://****.org/ziyuan/%s.html" % num
req = requests.get(url, headers=headers)
if "不存在" in req.text:
print("%s 您访问的页面不存在" % num)
return
soup = BeautifulSoup(req.text, 'html.parser')
info = soup.find('div', class_="panel-body")
info_list = info.find('div', class_='entry-meta').find_all('li')
title = info.find('h1', class_='metas-title').text.strip()
update_time = info.find('span', class_='comment-num').text.strip()
type = info_list[0].text.strip().replace("网盘分类:", "")
tag = info_list[1].text.strip().replace("资源分类:", "")
link = info.find('a', id='lj')['href'].replace('/go/?url=', '')
try:
password = info.find('span', id='tiquma').text.strip()
except:
password = ""
with open("wpfz_info1.csv", 'a', encoding='utf-8', newline='') as f:
csv_write = csv.writer(f)
csv_write.writerow([num, title, update_time, type, tag, link, password])
print("%s 已经完成" % num)
if __name__ == '__main__':
for i in range(1, 4817):
get_info(i)
time.sleep(1)
|
操作的过程如下:
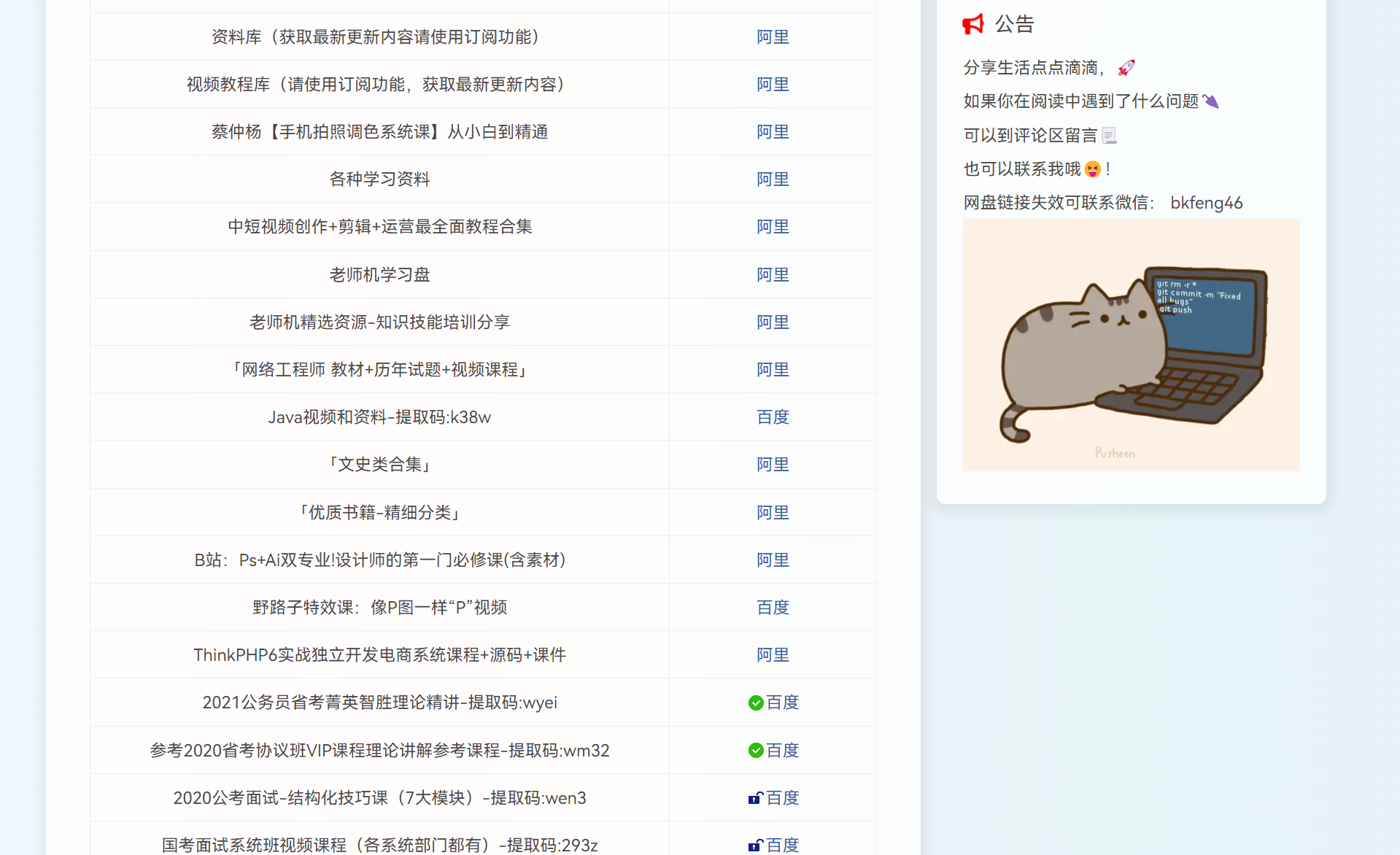
最终获取到的资源如下:
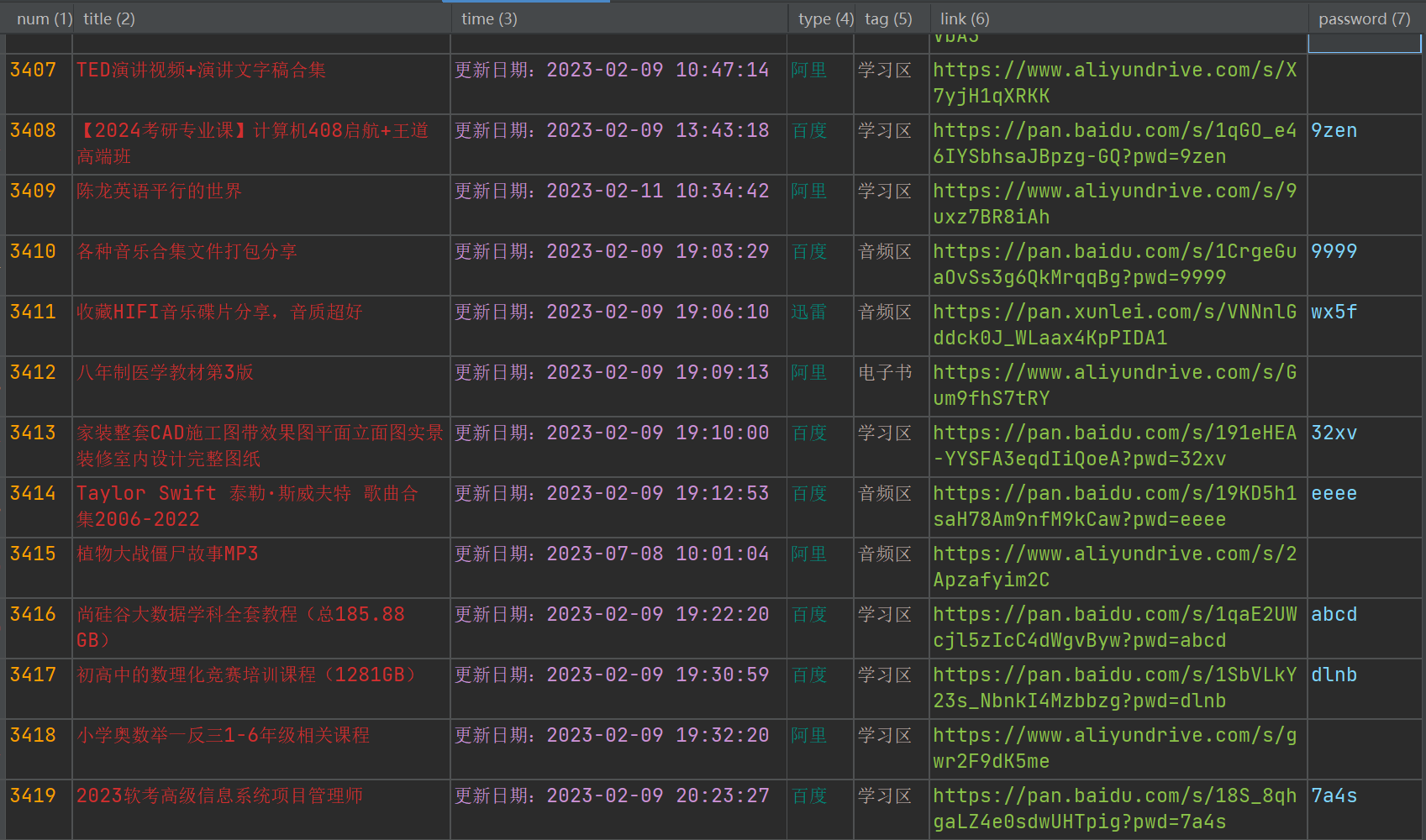
为了方便大家获取,我就把资源查询整理了一下放到博客了
https://bkfeng.top/link
有一说一,这份资源确实挺不错的
涵盖考研学习,游戏资源、影视动漫、编程教程方方面面







 wechat
wechat
